If you’ve ever had the misfortune to be managed by me, you can thank one Tom Gilb for inspiring my habit of asking “What problem does this solve?” You may know from my writings, too, that I’m a very problem-oriented (or “outcome-oriented”, if you prefer) software developer. That, too, stems from my stumbling across Mr Gilb’s work early in my career (and Mr Gilb himself later on).

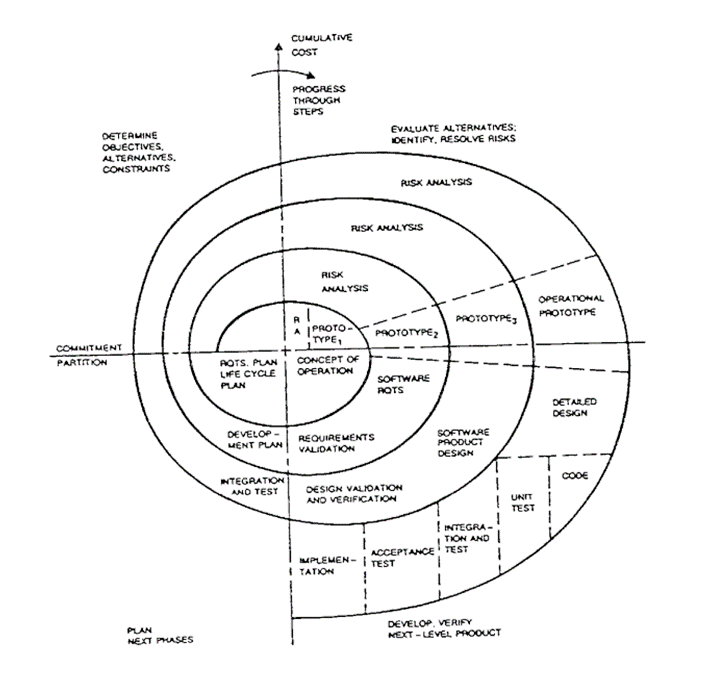
Principles of Software Engineering Management by Tom Gilb, published in 1988, is a seminal work in software engineering. It introduces the evolutionary development model, emphasizing iterative progress through small, manageable steps. Gilb advocates for quantifiable goals and metrics to guide software development, ensuring quality and efficiency. He underscores the importance of involving all stakeholders, including clients, in the development process for better outcomes. The book is known for its practical approach, blending management strategies with software engineering practices.
If that sounds at all familiar, you wouldn’t be the first person to ask if Gilb’s goal-seeking, evolutionary approach to software development was the forerunner to what we know today as Agile Software Development. And the answer is most definitely “yes”.
Key Points
- Evolutionary Development: Advocates for an iterative and incremental approach to software development, emphasizing continuous improvement.
- Quantifiable Goals and Metrics: Stresses the importance of setting clear, measurable objectives for software projects to ensure quality and effectiveness.
- Stakeholder Involvement: Emphasizes the need for involving all stakeholders, including clients, in the development process to align outcomes with user needs and expectations.
- Early and Continuous Delivery: Encourages frequent delivery of working software to get early feedback and facilitate better end results.
- Adaptability and Flexibility: Promotes adaptability in the development process, allowing for changes and revisions based on feedback and changing requirements.
- Risk Management: Highlights the importance of identifying and managing risks early in the software development life cycle.
- Effective Communication: Underlines the necessity of clear, consistent communication among team members and with stakeholders to ensure project success.
- Team Empowerment: Advocates for empowering development teams, giving them the autonomy to make decisions and solve problems creatively.
- Quality Focus: Prioritizes high-quality outputs, with an emphasis on robust testing and validation throughout the development process.
- Efficiency in Resource Management: Stresses efficient use of resources, including time and budget, to maximize productivity and value.
If you follow me on social media, you may have have seen me argue that “productivity” in software development is essentially the value a team creates for each dollar spent, and that “value” is very much in the eye of the beholder. Could be increased revenue, could be decreased costs, could be Oscars won, could be lives saved. It’s not really up to us, and PoSEM was the book that opened my eyes to the need to work closely with stakeholders to build an understanding of what has value to them.
Reframing development as an iterative process of solving problems (as opposed to delivering solutions – a subtle but profound distinction) can have a big impact on teams. Gilb once told me about a client of his who was investing millions in a system to more effectively prioritise email communications so that the top brass saw all the important stuff without it being buried under a mountain of trivial memos and birthday announcements. The project was running far behind schedule and was way over budget. Tom asked that simple question: “What problem are you trying to solve?” It had evidently been a long time since anyone thought about that. It’s extremely common for teams to lose sight of the end goal and for the work to become an end in itself. As one senior manager in the UK Post Office once told me after I asked what the end goal of his project was, “The end goal is to stick to the plan”. Anyway, it turned out their existing email solution could be configured to do what they needed quite easily. Problem solved!
There’s been many times in my career when taking a step back and asking “What problem are we trying to solve?” has precipitated dramatic changes of direction towards much more fruitful – and far quicker and cheaper – outcomes. It’s the most powerful question in software development.
Although sadly out of print, you can pick up second-hand copies of Principles of Software Engineering Management for very little. I highly recommend giving it a look if you’re curious about the historical context of Agile and Lean, and are interested in how to shift your focus from building products to solving problems. For all those folks who harp on about delivering “value”, this is one of very few books in our profession that talks about what that actually means.